
”hadoop 使用自定义分区“ 的搜索结果
需求 将统计结果按照手机号,以136、137、138、139...(分区) 输入数据 1863157985066 120.196.100.82 2481 24681 200 1363157995033 120.197.40.4 264 0 200 1373157993055 120.196.100.99 132 1512 200 139315...
背景 在Hadoop的MapReduce过程中,每个map task处理完数据后,如果存在自定义Combiner类,会先进行一次本地的reduce操作,然后把数据发送到Partitioner,由Partitioner来决定每条记录...MapReduce自定义分区 ...
Hadoop自定义分区 Hadoop组件partition简介 partition的作用是将mapper输出的key/value划分成不同的partition。每个reducer对应一个partition。 默认情况下,partitioner先计算key的散列值(hash值)。然后通过...
文章目录Hadoop 自定义Partitioner分区1 partitionr作用2 默认Partitioner分区3 自定义Partitioner4 注意 Hadoop 自定义Partitioner分区 1 partitionr作用 partition是分割map每个节点的结果,按照key分别映射给不同...
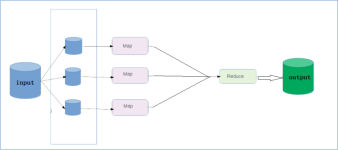
Hadoop提供的Partitioner组件可以让Map对Key进行分区,从而可以根据不同key来分发到不同的reduce中去处理,我们可以自定义key的分发规则,如数据文件包含不同的省份,而输出的要求是每个省份对应一个文件。...
测试数据 1,2,1,1,1 1,2,2,1,1 1,3,1,1,1 1,3,2,1,1 1,3,3,1,1 1,2,3,1,1 1,3,1,1,1 1,3,2,1,1 1,3,3,1,1 ... 在map中数据以‘,’分隔,分隔后的前两列作为key,相同的key会被分到同一个reduce中。...
在Hadoop的MapReduce过程中,每个map task处理完数据后,如果存在自定义Combiner类,会先进行一次本地的reduce操作,然后把数据发送到Partitioner,由Partitioner来决定每条记录应该送往哪个reducer节点,默认使用的...
MapReduce自带的分区器是HashPartitioner原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定...自定义分区类:注意:map的输出是<K,V>键值对 其中int partitionIndex = dict.get(text.to...
实现自定义分区比较简单了,继承Partitioner,实现getPartition()方法就行了,分区是按照key进行的。以wordcount为例。 输入文本1 hello world hello 3.输入文本2 hello world world 4 编写程序,hello 和world...

在Hadoop的MapReduce过程中,每个map task处理完数据后,如果存在自定义Combiner类,会先进行一次本地的reduce操作,然后把数据发送到Partitioner,由Partitioner来决定每条记录应该送往哪个reducer节点,默认使用的...
在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区、排序、分组这些,那今天我就接上一次的代码继续完善实现自定义分区。 首先我们明确一下关于中这个分区...
文章目录自定义数据类型(序列化)自定义数据类型自定义数据类型规则实例1使用hadoop提供的数据类型实现如上格式输出自定义数据类型 FlowWritable实现map方法实现reduce方法主函数 DriverMap的分片自定义分区实例2默认...
Hadoop提供的Partitioner组件可以让Map对Key进行分区,从而可以根据不同key来分发到不同的reduce中去处理,我们可以自定义key的分发规则,如数据文件包含不同的省份,而输出的要求是每个省份对应一个文件。...
2019独角兽企业重金招聘Python工程师标准>>> ...
首先我们明确一下关于中这个分区到底是怎么样,有什么用处?回答这个问题先看看上次代码执行的结果,我们知道结果中有个文件(part-r-00000),这个文件就是所有的词的数量记录,这个时候有没什么想法比如如果我想把...
在MR的job中,默认使用的分区类为:HashPartitioner.class 其源代码为: public class HashPartitioner<K, V> extends Partitioner<K, V> { public HashPartitioner() { } public int ...
Hadoop自定义排序、分区
标签: Hadoop
实际中往往我们规定一种排序方法,并且为了避免数据倾斜情况,需要我们自定义分区。这里我们讨论将一个城市四年来的温度按年份升序排序,同一年份的温度按照降序排序。自定义排序定义一个封装对象定义排序方法自定义...

Hive自定义分区器流程 1.自定义类 实现org.apache.hadoop.mapred.Partitioner(必须为这个,Hive中使用的是老的API)接口 package com.ailibaba; import org.apache.hadoop.hive.ql.io.HiveKey; import org.apache....
Hive自定义分区器流程 1. 环境说明 当前环境采用Hadoop3.1.3以及Hive3.1.2版本! 2. 自定义类 自定义类实现org.apache.hadoop.mapred.Partitioner(必须为这个,Hive中使用的是老的API)接口,这里只是做测试,所以所有...
MapReduce基础编程(自定义序列化、自定义分区、自定义排序、自定义分组)
0 简介: 0) 类比于新生&lt;k,v&gt;入学,不同的学生实现分配好了宿舍,然后进入到... 这就是分区的原因。 a) 默认下分配一个区 b) 分配几个区,则对应几个reduce任务,每个任务在执行的时候都会公用red...
https://mp.csdn.net/postedit/86479388(hadoop的数据倾斜之自定义分区解决(记录七----1)) package com.gsd.skew; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import ...
为什么我们要进行自定义分区 当spark进行数据处理key-value类型数据时,会遇到数据由于key值的分布不均倾斜的情况,为了使得资源的合理布置我们会进行重分区,根据spark内部提供的分区器 HashPartitioner & ...
02-Hadoop MapReduce 原理 分区 自定义分区器 Partitioner发生在map写出去到环形缓冲区之前要计算分区,所以自定义分区类的泛型就设置成Map 写出数据的KV 结论:Mappper写出去的KV和Partitioner的KV一致 ...
推荐文章
- ssm小学生课外知识学习网站+vue-程序员宅基地
- goland 常用快捷键_goland进入ctrl+b函数后,什么快捷键返回上一个函数-程序员宅基地
- Python3-word文档操作(六):word文档中表格的操作-单元格文字居中,字体颜色等的设置_doc.tables[0].cell(a, b).vertical_alignment = wd_a-程序员宅基地
- Ubuntu系统使用技巧 Vim基本技巧介绍_ubuntu系统vim操作-程序员宅基地
- Nacos 使用指南-程序员宅基地
- vue基础指令_在vue中,可以通过____语法将数据输出到页面中。-程序员宅基地
- Navicat将Oracle数据导入到MySQL_navicate导出的oracel脚本可以导入到其它数据库内吗-程序员宅基地
- 有道云生成html,有道云笔记添加收藏功能实现原理-程序员宅基地
- Kali安装完成后的基本配置_kali tab预选-程序员宅基地
- 【Android】APK的打包流程_apk源码怎么打包-程序员宅基地